


|
|
Intro | |||
| About PseudoBase | Retrieve by Class | Retrieve by Property | Submit Pseudoknots | |
|



 Purpose
Purpose
Since the first discovery of RNA pseudoknots
(Pleij et al., 1985) more and
many more pseudoknots have been found.
However, not all of those pseudoknot data are easy to trace.
Sometimes the information is hidden in a publication where the title
gives no hint that pseudoknot information is there.
This was the first reason that we thought that a general accessible
information source for pseudoknots would be handy.
Apart from the usual secondary RNA structure, our program
STAR also predicts
so-called classic or H-pseudoknots.
For validation of such predictions corroboration by experimental evidence
and/or phylogenetic support is also needed.
Also, functions of RNA pseudoknots depend on specific
pseudoknot features; such studies make pseudoknot data very important.
So for several reasons we felt that easy and quick access to data about pseudoknots was needed. Therefore we decided to make such a service available to the scientific community; our purpose for this database is:
To provide quick access to reliable pseudoknot data, we intend to build a database with reliable pseudoknot information.
An important issue here is reliability.
We decided that the task of judging reliability of submitted pseudoknot
data should not be laid upon us.
Rather there should be a standard requirement that is clear to everyone
and which guarantees a certain reliability.
For that reason we decided to include an item "supported by:";
this indicates by what criterion the pseudoknot is determined.
Using this criterion the reader can judge for himself how reliable the
particular pseudoknot report is.
Furthermore we decided to include only pseudoknots that are published so
any scientist accessing PseudoBase can check the literature or even contact the author.
 Feedback
FeedbackIf you have suggestions that may improve the quality of this database, or other suggestions that may be helpful, if you find any errors or omissions, please contact us....
If you would like to write to us by snail-mail, our addresses are:
|
F.H.D. Van Batenburg / AP Gultyaev
Theoretical Biology Institute of Evolutionary and Ecological Sciences (E.E.W.), Leiden University, Van der Klaauw Laboratory, Kaiserstraat 63, 2311 GP Leiden, P.O. Box 9516, 2300 RA Leiden, The Netherlands |
C.W.A. Pleij
Leiden Institute of Chemistry Leiden University, Gorlaeus Laboratories, Einsteinweg 55, 2333 CC Leiden, PO Box 9502,2300RA Leiden, The Netherlands |
 History
History
The idea of PseudoBase was born in 1997. In that year Eke van Batenburg, Sacha Gultyaev (both from the Institute of Theoretical Biology) and Kees Pleij (from the Leiden Institute of Chemistry) decided upon the development of a database for pseudoknots.
Real work started at the end of 1997 when
Jacky Ng designed
the first prototype as part of his study project in bioinformatics
working for Eke van Batenburg.
In 1998 Jan Oliehoek inherited the project
--also as a part of his study in bioinformatics--
and extended and improved that prototype.
At the end of 1998, Eke van Batenburg took over and shaped the design to its final form.
After this preliminary design work, the biggest job was to consult the literature and submit pseudoknots to the database. Jacky Ng had already done some preliminary work and had entered a few pseudoknots. Here Sacha Gultyaev took over and added most of pseudoknots.
In 2006 and 2007 mismanagement by the computer service department of Leyden
university resulted in several occasions where PseudoBase was inaccessable for many weeks at a time.
Complaints were ignored or resulted in the suggestion to look for another hosting provider.
So finally, when the url changed (a second time in 2 years!) and Pseudobase was inaccessable again
it was decided to move to the current hosting provider.
This change was also used to update and improve the website:
we removed dead links, introduced CSS, improved and extended some texts and added the sortable property table.
The data you can enter on the submission form are rather straightforward. To help you, we have added an example on the right and an info button for every item.
Nevertheless, something might be unclear to you. So if you have any questions that are not answered here, please do not hesitate to contact us for clarification.
The following items in the submission form and in the database itself might need some clarification:
1806 AGGCGGGGCGAGCUGCAGCCCCAGUGAAUCAAAUGCAGC 1844
1806 AGGC GGGGC GAGCU GCAGC CCCAG UGAAU CAAAU GCAGC 1844
1806 AGGC
GGGGCGAGCU
GCAGCCCCAG
UGAAUCAAAU
GCAGC
1844
For loops that are very long and complex you can omit some
nucleotides and and specify the relevant parts separately.
For example, if sequence
1806 AGGCGGGGCGAGCUGCAGCCCCAGUGAAUCAAAUGCAGCAGGCGGGGCGAGCUGCAGCCCCAGUGAAUC 1874
contains some 40 nucleotides in the center that you don't want to
type, you can specify:
1806 AGGCGGGGCGAGCUG 1820 1860 CAGCCCCAGUGAAUC 1874
If you use this option and one of the stem parts is small, we suggest that
you enter more than 10 nucleotides so the display has sufficient places for
numbering.
Although not shown in the last example, you can use blanks and returns wherever
it suits you.
If you copy/paste the sequence from another source and the sequence contains T, there is no need to convert them to U; our database accepts T as well as U.
1980 1990 2000 2010 2020 2030
# 123456789|123456789|123456789|123456789|123456789|123456789|1=2031
$ UAGGGAGGUCAGGGUCAGGAGCCCCCCCCUGAACCCAGGAUAACCCUCAAAGUCGGGGGGC
% -----------((((((((-[[[[[[[))))-))))------------------]]]]]]]
the structure was specified as:
1982-1985; 2003-2006
1986-1989; 1998-2001
1991-1997; 2025-2031
If you agree, your email is used in another way too. Apart from mentioning your name as submitter of the data, we would like to add your email address in the PseudoBase. In this way anyone with questions about that particular pseudoknot can contact you easily. If you don't like having your email public in the database you can ask us not to enter your email in the database by "un-crossing" the email-consent-box on the submission form.
Do not leave the email field empty. Due to frequent spam we decided to check the validity of this field. If you leave it empty our program will erroneously decide that you are a web-bot. (Just for the paranoid scientist among us: if you really want to be anonymous you can enter a bogus email address, even a single "@" will suffice; remember however that in doing so we are unable to contact you if we find some reason to consult you about the submitted data.)
As you might have noticed, these data are presented in two ways in the database.
First the raw data is given: the nucleotide sequence and the
position numbers of the two stems of the pseudoknot.
Secondly we present a simple sketch of the same data in a
modified "bracketview".
In this modification we use parenthesis for the first stem of the
pseudoknot and brackets for the other stem.
We will show what this looks like.
Imagine you have the following hypothetical sequence-part:
acguCCCacguaAAAAGGGacguUUUUacgu
and imagine that this forms the following pseudoknot:
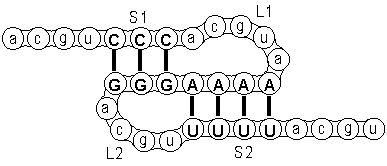
We display this pseudoknot in our bracket-view modification as follows:
acguCCCacguaAAAAGGGacguUUUUacgu
----(((-----[[[[)))----]]]]----
You see the sequence in the first line, and the structure in the second line.
The first stem is CCC-GGG which is shown underneath by
(((( and )))).
The second stem AAAA-UUUU is indicated underneath using
[[[[ and ]]]].
The submission form only requires you to specify the stem pairings. It does not ask you to compute loop and stem sizes. The final pseudoknot data items do specify the loop sizes and stem sizes, but this is derived automatically from the stem specifications.
Loop sizes and stem sizes are also used for surveys where you can choose pseudoknot items in lists where order is based on size of stems or loops.
How are those stem sizes and loop sizes computed? We decided to opt for
the most simple definition. Only "pseudoknot-stems" are considered
as stem and all regions between those stem-halves are counted as loops.
For stem-size we counted all nucleotide pairings of each pseudoknot-stem.
Unpaired nucleotides in bulges and internal loops were not counted.
For illustration consider the following PseudoBase pseudoknot item:
Stem sizes: 4 5 4
Traversing along the 5'-3' direction the first stem is S1 with 4 nucleotide
pairings, the next stem is S2 with 5 pairings followed by S3 with 5 nucleotides
because the unpaired nucleotide 70 is ignored.
Loop sizes: 1 2 8 0 32
10 20 30 40 50 60 70
123456789|123456789|123456789|123456789|123456789|123456789|123456789|123
ACAGAGCGCGUACUGUCUGACGACGUAUCCGCGCGGACUAGAAGGCUGGUGCCUCGUCCAACAAAUGAUCACA
((((:[[[[[::))))::::::::(((((]]]]]((((::::((((::::)))):)))):::::::))):)):
|S1| |S2-| |s1| |S3-||s2-| |-s3-|
^L1 ^^L2 |-L3---| \L4 |-L5---------------------------|
Normal stems of internal hairpins are ignored, only pseudoknot
stems are counted.
For example stem 43-46;51-54 is ignored because it forms an internal stem-hairpin.
For loops we used a similar simple labeling system. The first unpaired region between different stems (counting from 5' end and upwards) was labeled L1, the next one L2 and so on. Notice that we report L4 as a loop of size zero between nucleotide 29 and 30 because here is the end of the 5' part of stem S3 and the beginning of the 3' part of stem S2. So we do count all potential as well as all loop regions. Furthermore for the size we consider all nucleotides in the region irrespective of the structure they may form. Thus loop L5 counts for size 32 (nucleotides 35-66) because the paired nucleotides in that region form a normal hairpin with an internal loop and are not paired into a "pseudoknot-stem".
In the property table of "Retrieve by property" we restricted ourselves to record only L1, L2 and L3 loops and S1 and S2 stems. For more complex pseudoknots we indicated the other loops and stems as "x" in columns "L+" and "S+".
 PseudoBase structural details
PseudoBase structural detailsPseudoBase is extremely simple in structure.
Basically it is a collection of static html pages, one page for each pseudoknot.
Also the naming scheme is simple, the html file of the first pseudoknot is "PKB00001.html",
the next one is "PKB00002.html" and so on.
As we have choosen not to use a dynamic structure using php with a sql database but static html pages instead, anyone who needs data from PseudoBase can download the pseudoknot files and extract the relevant data using a simple text-editor.
Even the 5 introductory pages are static html and uses javascript only to sort the property table (my thanks to Stuart Langridge for his extremely user-friendly sorttable software).
Using the simple structure of PseudoBase, Texas university designed a new shell around the data of PseudoBase for improved access. It provides more extensive and improved searching capabilities and more and better presentations for viewing the knotted RNA's. PseudoBase++ is reached at http://pseudobaseplusplus.utep.edu.
This paragraph mentions a few of our publications regarding pseudoknots.
Publications regarding pseudoknots:
